
1. Introduction
In the era of Big Data and the Internet of Things (IoT), the fundamental nature of data has shifted from simple user-generated inputs to a continuous, high-velocity stream of machine-generated records. For modern SaaS platforms, this creates a critical architectural crossroads. Many engineering teams fail to distinguish between two fundamentally different types of data, often attempting to force all information into a single storage paradigm. This lack of strategic separation leads to a logical mismatch. The storage solution becomes a bottleneck for the business rather than an asset for analysis.
Data utility is now split into two distinct categories. First, there is transactional state—the high-value, frequently modified data that defines the current “truth” of an application. Second, there are “Records“: the immutable, high-volume logs from Nginx frontends, server telemetry, and IoT sensors. While a robust RDBMS like PostgreSQL is technically capable of ingesting these records, it is an inappropriate tool for the task. The sheer scale of modern logging means that using a relational database for append-only records results in an unacceptable trade-off: you pay a premium in storage costs and performance overhead for relational features that “Records” never actually utilize.
To maintain a lean and performant infrastructure, a bifurcated storage strategy is essential. By offloading immutable records to a specialized data pool, organizations can preserve their primary database cluster for core transactions while gaining the ability to perform deep, multi-dimensional analysis on their operational history. This article will examine the logical necessity of this separation and provide a practical framework for implementing an architecture that turns raw telemetry into actionable business intelligence.
2. The Strategic Importance of Data Differentiation and the ELK Solution
In a sophisticated infrastructure, every byte of data carries a “functional cost.” Relational Database Management Systems (RDBMS), like PostgreSQL, follow “ACID” compliance standards: Atomicity, Consistency, Isolation, and Durability. This architecture is indispensable for transactional data like user profiles and financial balances. In these cases, row integrity is paramount. However, the technical overhead required to maintain these relational guarantees makes them inherently inefficient for the “Record” layer. When high-velocity streams from Internet of Things (IoT) devices or server logs are forced into an RDBMS, the database must constantly update indexes and manage write-ahead logs for data that will likely never be modified. This results in “Index Bloat,” where the cost of maintaining the database outpaces the value of the information stored within it.
Scaling with WORM Architecture
By contrast, “Records” are immutable and time-series oriented. They require a Write-Once, Read-Many (WORM) architecture that prioritizes ingestion speed and full-text searchability over complex relational joins. This is where the ELK stack—comprising Elasticsearch, Logstash, and Kibana—provides a superior architectural alternative. By offloading these massive datasets to a specialized search engine, the primary Database Cluster is liberated from the “gravity” of non-transactional telemetry. This separation ensures that an analytical query across millions of Nginx logs does not lock tables or consume the Central Processing Unit (CPU) cycles needed to serve live user requests.
The ELK solution addresses this challenge through a distributed, document-oriented approach:
- Elasticsearch (ES): A distributed, RESTful (Representational State Transfer) search and analytics engine built on Apache Lucene. It utilizes inverted indexing to provide near real-time search capabilities across petabytes of unstructured data.
- Logstash (LS): A server-side data processing pipeline that ingests data from multiple sources simultaneously, transforms it (such as converting raw Nginx strings into structured JSON (JavaScript Object Notation)), and sends it to a “stash” like Elasticsearch.
- Kibana (K): An open-source data visualization and exploration tool used for log and time-series analytics, application monitoring, and operational intelligence.
By implementing this bifurcated strategy, the architecture gains horizontal scalability. While an RDBMS often requires expensive vertical scaling to handle increased log volume, the ELK stack can be expanded by simply adding nodes to the cluster. This ensures that as IoT and application telemetry grow, the system’s observability increases without compromising the stability of the core business logic.
3. Implementation — The Unified Cloud-Based Data Pool
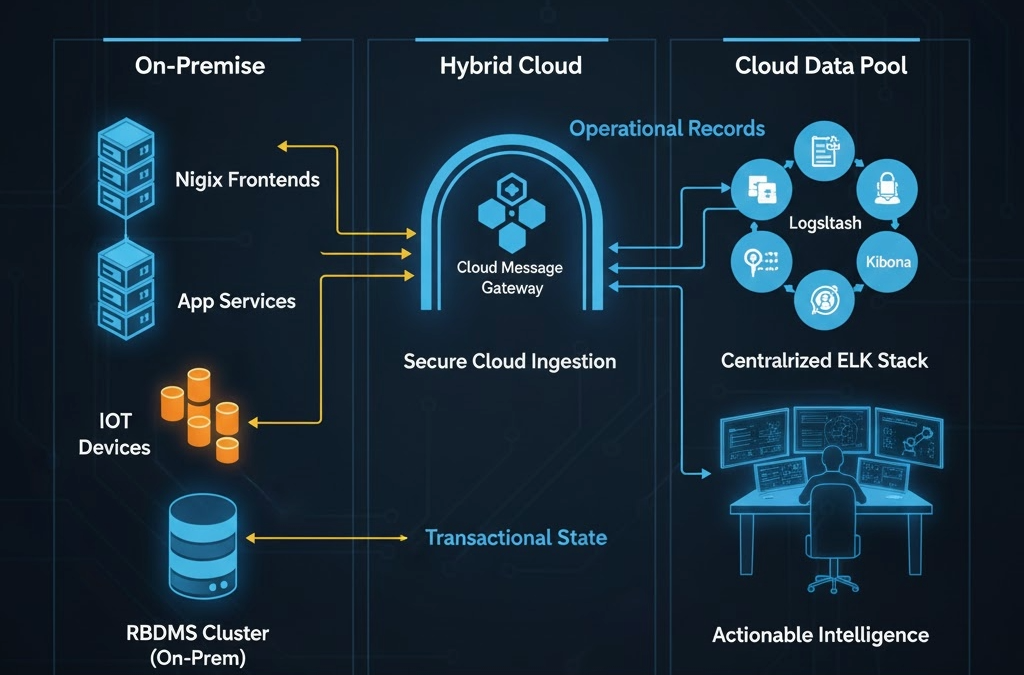
For a modern SaaS platform, the true value of the “Record” layer is realized when telemetry from disparate environments is consolidated into a single, cloud-based analytical hub. In this architecture, the architecture hosts the ELK stack within a Tier 1 Cloud Service Provider (CSP) such as AWS or Azure, where it stores and manages all machine-generated data.
3.1. Security and the SMB Reality
As discussed in my previous analysis on Hybrid Cloud and SMB Security Misconfigurations, for most small to medium-sized SaaS providers, maintaining a dedicated, 24/7 internal security team is often financially and operationally unrealistic. In this model, high-intensity computation occurs On-Premise while “Records” stay in the cloud. This allows enterprises to inherit the robust security of Tier 1 providers. This approach significantly lowers the risk profile; this strategy offloads the burden of securing storage “at rest” to providers who invest billions in infrastructure defense, allowing internal engineers to focus on core product logic rather than hardening storage clusters.
3.2. The Global Ingestion Strategy and Cost Efficiency
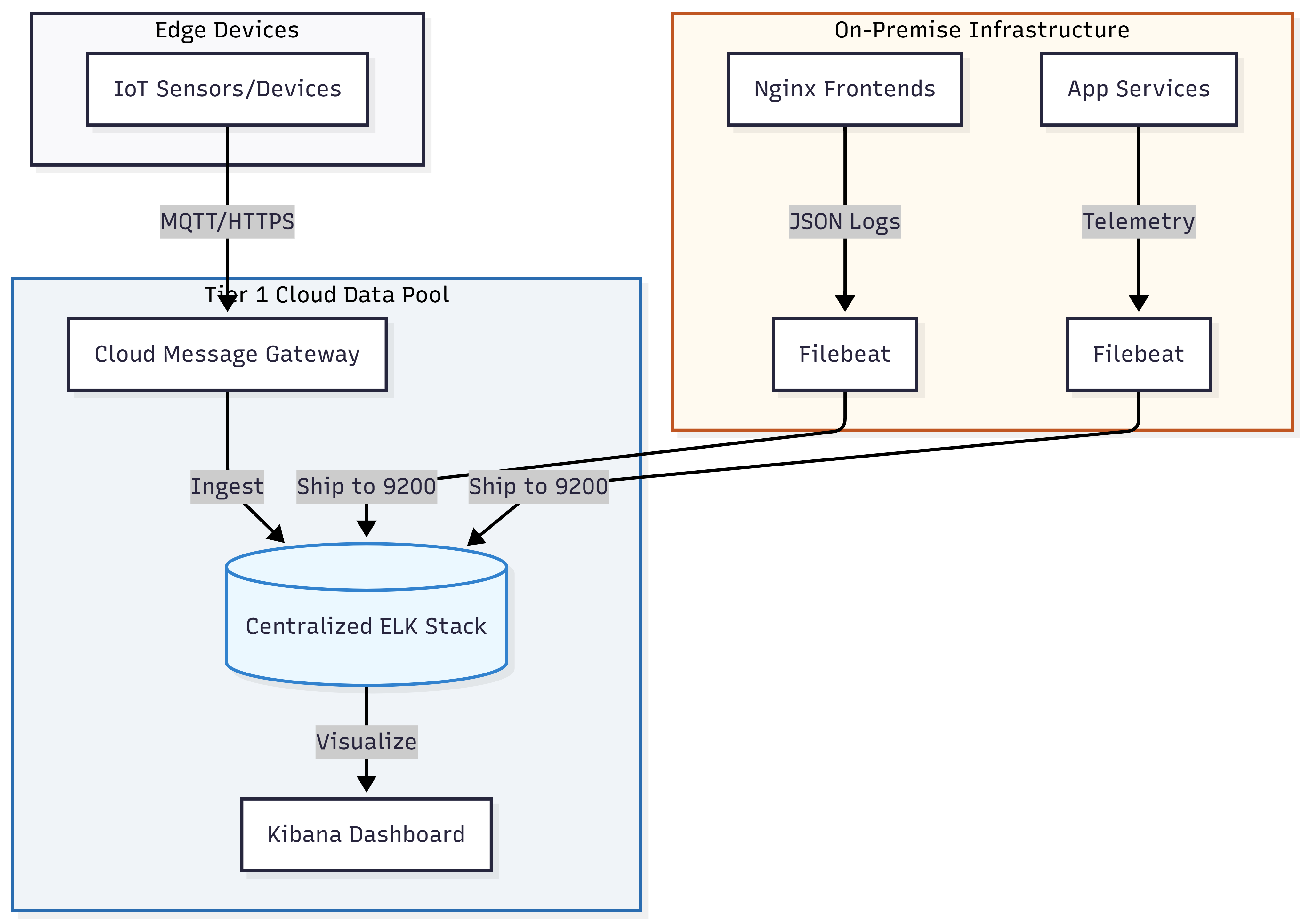
The architecture bridges the gap between different physical locations through a unified ingestion pipeline. Internet of Things (IoT) devices, distributed globally, transmit their records to a cloud-native message gateway (e.g., AWS IoT Core). Simultaneously, the On-Premise environment—housing the Nginx frontends—utilizes local Filebeat agents to ship logs directly to the cloud-based Elasticsearch endpoint. Beyond security, there is a clear economic incentive: the storage cost for static, immutable “Records” in cloud-optimized data pools is significantly lower than the cost of expanding high-performance Relational Database Management System (RDBMS) volumes or local Storage Area Network (SAN) arrays.
3.3. Edge-to-Cloud Resilience
By deploying Filebeat locally on each On-Premise node, the system establishes a decoupled ingestion path. This ensures that the primary application performance is never throttled by the logging process. The local agent handles the transmission of data to the cloud cluster independently of the application’s request-response cycle. This asynchronous delivery ensures that the Big Data record remains continuous and audit-ready, maintaining high-fidelity visibility into frontend operations without impacting the latency of the core business service.
3.4. Actionable Intelligence via Kibana
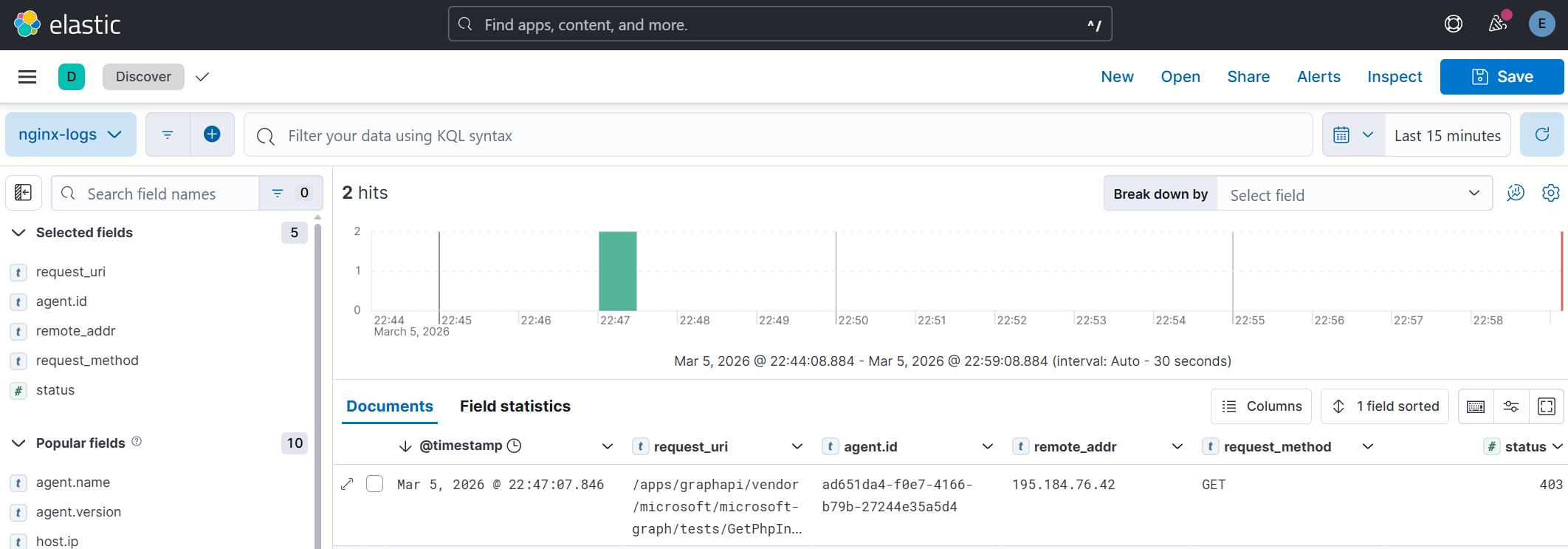
With both IoT telemetry and Nginx access logs residing in the same cloud-based cluster, Kibana becomes a unified “Single Pane of Glass.” Because these records were born as structured JSON, they can be cross-referenced instantly. Engineers can correlate frontend web traffic patterns with backend hardware performance or sensor data, transforming raw logs into a dimension of business intelligence that informs both infrastructure scaling and commercial strategy.
Conclusion
The strategic separation of Transactional State and Operational Records is a foundational requirement for modern, data-driven enterprises. As we have explored, even a high-performance Relational Database Management System (RDBMS) like PostgreSQL faces a significant architectural burden when tasked with the high-velocity ingestion inherent to the IoT and Big Data era. By treating logs and telemetry as a distinct, immutable asset class, we protect the core business logic from the overhead of non-transactional data.
Implementing a hybrid ELK-based architecture—where compute remains local while the system centralizes “Records” in a Tier 1 Cloud Provider—offers the best of both worlds. This approach ensures that while our primary database clusters remain lean and optimized on-premise, our operational visibility remains limitless and secure in the cloud. By transforming raw Nginx telemetry and IoT streams into structured intelligence, organizations can significantly lower their total cost of ownership while gaining the deep, multi-dimensional insights necessary to scale in a competitive SaaS landscape.