

1. Introduction: The Fragile State of SMB Data
The Status Quo of SMB Storage
For Small-to-Medium SaaS providers (SMEs), storage is frequently the most vulnerable link in the architectural chain. In the early stages of a project, the natural tendency is to rely on “straightforward” solutions: local disks, simple hardware RAID, or centralized NAS. While these are intuitive to deploy, they become systemic liabilities the moment a service transitions from an “experimental project” to a “production-grade enterprise SaaS.” SMEs often operate in lightweight environments with limited budgets, where security involves balancing risks against costs rather than assuming unlimited resources for ideal setups.
The Reliability Paradox
Many teams fall into a false sense of security, equating hardware redundancy with true disaster recovery. A RAID array or a scheduled nightly backup is a fragile defense against modern site-level threats. In a real-world disaster—be it a total cluster failure, a localized data center outage, or a sophisticated ransomware attack—these traditional methods fail to provide the Business Continuity that enterprise clients demand.
The Strategy: Designing for Survival
Instead, architecture does not try to prevent every possible failure; it focuses on giving the system the inherent ability to survive a total site loss. To bridge the gap between resource constraints and professional-grade Service Level Agreements (SLAs), we must rethink how data is tiered and where it lives.
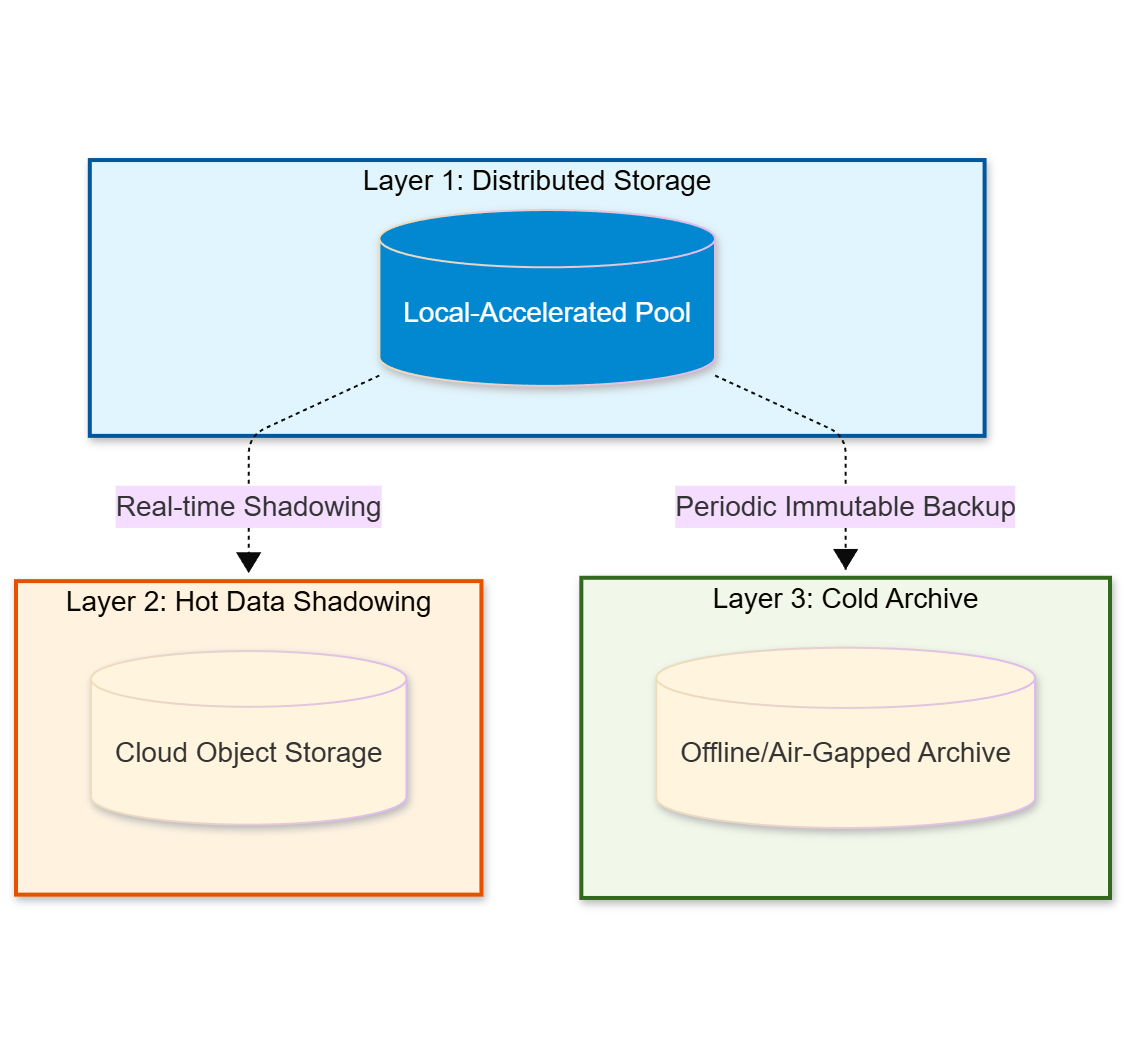
We propose a Multi-Layer Storage Vault that ensures data integrity across three distinct environments:
- Local Distributed Storage: For high-performance, daily operations.
- Cloud Hot Data Shadowing: A real-time “memory” for site-level failover.
- Local Cold Archive: The final bastion against ransomware and total cloud compromise.
As a result, by architecting this three-tier hierarchy, we ensure that while hardware is disposable, the data—the “soul” of the SaaS—is eternal.
2. Distributed Storage: The Strategic Shift from NAS to HCI
A single, critical requirement drives the decision to move from a centralized NAS to a Distributed Hyper-Converged Infrastructure (HCI): eliminating the Single Point of Failure (SPOF). As a result, in a professional SaaS environment, uptime becomes the ultimate currency, and a centralized storage model turns into a gamble that most providers eventually lose.
The Vulnerability of Centralized Logic
In a “3+1” setup (3 compute nodes + 1 dedicated storage server), a single motherboard, power supply, or storage controller can bring down the entire business.
- The “Blackout” Risk: If the storage server fails—due to a hardware glitch, a backplane short, or a simple firmware hang—all three compute nodes lose their “disks” instantly. Even though your servers are fine, your service is dead.
- The Maintenance Trap: Updating or repairing a centralized NAS usually requires a scheduled “Total Outage,” as there is no other place for the data to live while the box is down.
Distributed Resilience: Survival by Design
By moving to a 3-Node HCI Cluster (Ceph-based), we shift from a “protection” mindset to a “resilience” mindset. In this model, the storage layer is woven into the compute nodes, creating a self-healing fabric. However, to satisfy both performance and survival, the cluster must be architected with a Tiered Pool Strategy.
The High-Performance “Hot Pool” (Erasure-Coded 2+1 Layer)
The Hot Pool is the engine of the SaaS, hosting active databases, transaction logs, and VM system disks.
- Mechanism: We utilize Erasure Coding (EC 2+1). Data is split into 2 data chunks plus 1 parity chunk distributed across the 3 nodes, providing 66% usable capacity while still tolerating the total loss of one node.
- Resilience: If one node is completely lost, the remaining two nodes continue serving I/O without downtime. The cluster enters a degraded state and automatically begins recovery once hardware is restored.
- Performance Note: EC introduces additional compute and network overhead compared to replication, but NVMe/SSD acceleration keeps latency within acceptable production thresholds.
As my friend, one of the best private cloud engineer mentioned that “2+1 erasure coded pools. That does not give a lot of room for issues. If you do maintenance and have an issue on a second node, you risk losing the pool. I usually don’t sleep well below 4+2 erasure codes pools on 7 nodes minimum.” I deeply agree with that, “2+1 erasure-coded pools” is the minimum setting, which provides small teams with basic resilience.
The High-Density “Cold Pool” (Erasure-Coded Capacity Layer),
Not all data requires the extreme performance of the Hot Pool. Static assets, user uploads, and historical logs live in the Cold Pool.
- Mechanism: We also utilize Erasure Coding, optimized for capacity rather than IOPS.
- Resilience: The pool can reconstruct data after a disk or node failure while maintaining significantly higher storage efficiency than replication.
- Purpose: This acts as the local capacity tier, allowing the SaaS to scale its data footprint cost-effectively without compromising cluster integrity.
Comparative Analysis: Centralized NAS vs. Distributed HCI
| Feature | Centralized NAS (3+1 Setup) | Distributed HCI (3-Node Ceph) |
|---|---|---|
| Fault Tolerance | Single Point of Failure (SPOF): The NAS is a single box. One controller failure = Total Site Outage. | Self-Healing: Data is distributed across nodes. The system survives a total node failure without service downtime, though performance may temporarily degrade during recovery. |
| Recovery Logic | Reactive: You must manually repair or replace the NAS hardware before recovery can begin. | Proactive: The cluster detects failure and automatically re-routes I/O while beginning background data recovery. |
| Storage Tiering | Rigid: Limited by the physical bays and RAID controller of the NAS box. | Software-Defined: Dynamically allocates performance and capacity pools across all node resources. |
| Scaling & Risk | Scaling increases risk: More compute nodes create more “clients” dependent on one fragile storage box. | Scaling increases resources: Additional nodes increase performance and recovery throughput, but redundancy design must be intentionally adjusted. |
| SLA Integrity | Fragile: Hard to guarantee professional-grade uptime when a single power supply can kill the site. | Resilient: Designed so no single hardware component can stop the service. |
3. Case Study: The Hybrid Resilience Framework
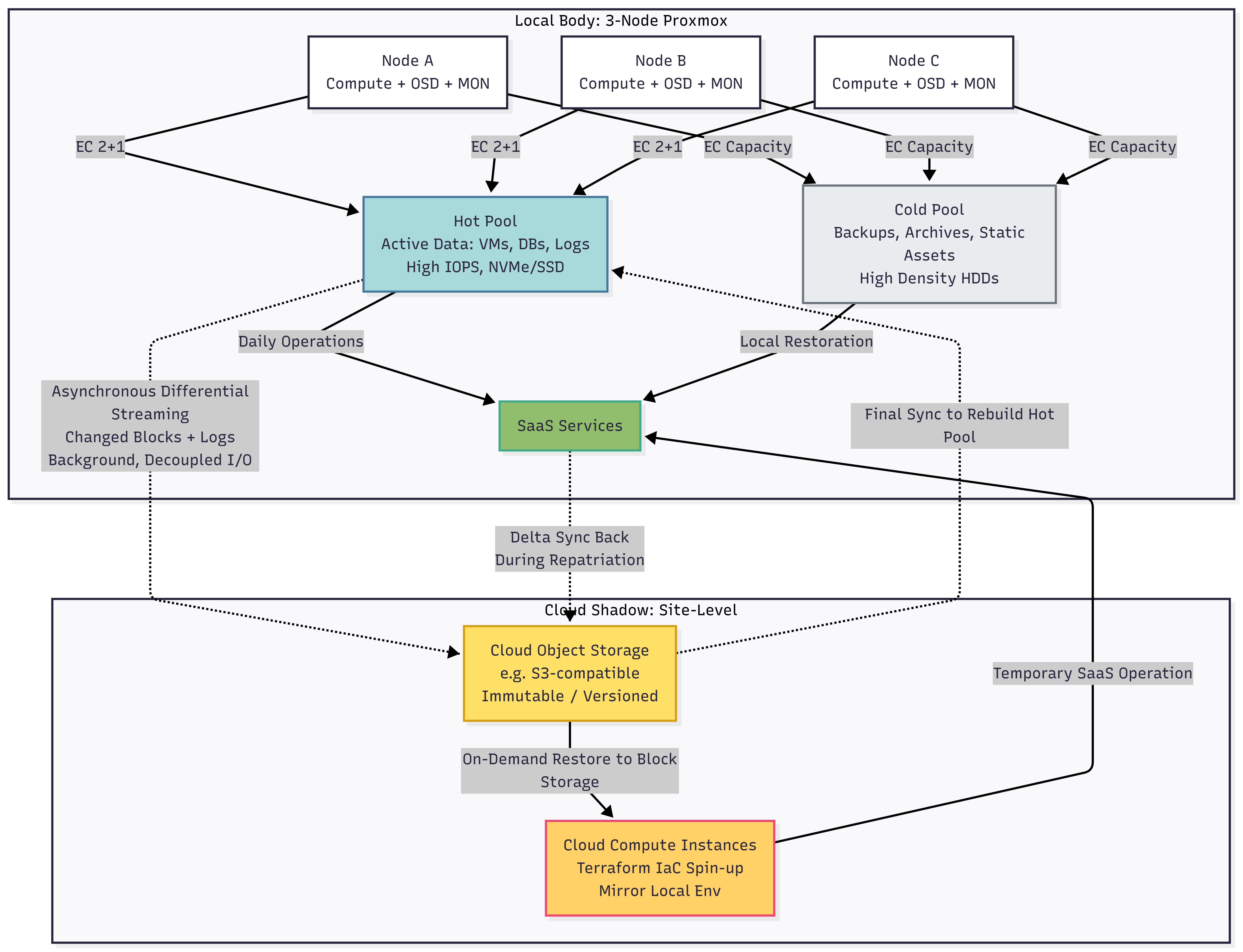
This case study examines a production-grade SME environment utilizing a Multi-Layer Storage strategy. The goal is not just to survive a disk failure, but to survive a total site disaster and provide a clear path to migrate services back to local hardware once it is restored.
Overall, the framework operates in 2 distinct layers:
- The Local Body: A 3-node Proxmox + Ceph HCI for high-performance daily operations.
- The Cloud Shadow: Asynchronous projection of hot data for site-level failover.
Layer 1: The Local 3-Node Proxmox + Ceph HCI
The local infrastructure consists of three Hyper-Converged servers. By running Proxmox VE and Ceph, we achieve a “Compute + Storage” unity where every node is a peer. Therefore, this design delivers reliability and affordability by leveraging a 2+1 redundancy model.
Dual-Pool Storage Architecture
Accordingly, we split the storage logically based on the nature of the data, not just the hardware:
- The Hot Pool (Production Data): Dedicated to Active Business Data (Running VMs, Live Databases). This pool is optimized for IOPS and low latency. It uses EC 2+1 across the 3 nodes, ensuring the business stays online after a single-node loss, with no downtime but temporary performance degradation during recovery.
- The Cold Pool (Management & Safety): Dedicated to Backups, Archives, and System ISOs. This pool acts as the local repository for everything that isn’t “live.” It ensures that snapshots and system images are distributed across the cluster, allowing for near-instant local restoration without touching the internet.
The 2+1 Survival Logic: 66% Availability
The architecture is mathematically balanced to handle a 1/3 hardware failure (33%) while maintaining full service operation.
- Compute HA (The 33% Buffer): We strictly reserve 33% of the total RAM and CPU across the three nodes. If Node A fails, Proxmox HA automatically restarts its VMs on Node B and Node C. Because of the 33% headroom, the surviving nodes don’t over-saturate, and SaaS performance remains within acceptable SLA thresholds.
- Storage Quorum: Ceph requires a majority of monitor nodes (MONs) to maintain quorum. In a 3-MON design, as long as 2 monitors (66%) remain online, the cluster stays writable.
Commodity Supply Chain Strategy
Instead, this system achieves reliability not through expensive service contracts but through Supply Chain Agility:
- Online Sourcing: All components (NVMe, HDDs, RAM) are standard parts available through common e-commerce platforms.
- Self-Healing: When hardware fails, the cluster uses its internal spare capacity to begin rebalancing and recovery automatically. Replacement parts can be installed within 24–48 hours without requiring enterprise vendor intervention. For enhanced monitoring and automated healing via webhooks and IaC, see Self-healing SaaS via WebHook API and IaC.
Local Failure Survival Matrix
| Failure Event | Architectural Response | Business Impact |
|---|---|---|
| Single Disk Failure | Ceph re-balances and reconstructs data in the background. | No downtime. Temporary, minor performance impact during recovery. |
| Complete Node Failure | Proxmox HA restarts VMs on the surviving 66% hardware. | Minimal. ~60s reboot; No data loss. |
| Two Node Failure | Quorum is lost; Local cluster freezes to protect data. | Critical. Triggers Cloud Failover (Layer 2). |
Layer 2: Cloud Hot Data Shadowing (Site-Level Failover)
While the local Proxmox cluster handles hardware failures, Layer 2 is designed for the total loss of the physical site. It ensures that the “live” state of the SaaS is always projected into a secondary, cloud-based environment.
Asynchronous Data Projection
The core mechanism is the continuous synchronization of the Hot Pool to Cloud Object Storage. This is not a static backup, but a dynamic “Shadow”:
- Differential Streaming: The system streams only changed blocks and database logs. This keeps the Cloud Shadow updated within minutes of the local state, providing a low RPO (typically minutes, depending on network conditions).
- Decoupled I/O: The sync process runs in the background. Because it is asynchronous, the local NVMe performance is never directly throttled by internet upload speeds.
The “Phoenix” Recovery Workflow
In the event of a total site disaster (fire, flood, or prolonged power outage), the cloud environment is used to “resurrect” the service.
- On-Demand Infrastructure: The network and environment settings are maintained as code (IaC). When a disaster is declared, scripts spin up cloud compute instances that mirror the local environment.
- Data Restoration: These cloud instances restore the shadowed data from object storage onto cloud block storage before services start, enabling the SaaS to resume operations in the cloud.
Repatriation: Moving Back to Local Hardware
However, the cloud serves only as a temporary lifeboat. Once the local site is restored—using standard components bought quickly online to rebuild the 3 nodes—the data must return home.
- Delta Syncing: Instead of a full multi-terabyte download, the system identifies the “delta” (the data created while running in the cloud) and syncs it back to the local Proxmox nodes.
- Final Cutover: Once the local Hot Pool is back in sync with the Cloud Shadow, traffic is routed back to the local cluster, ending the failover cycle.
Site-Level Failover Matrix
| Incident | Action | Result |
|---|---|---|
| Total Local Failure | Activate Cloud Failover. | SaaS runs in the cloud; low RPO (minutes) data exposure window. |
| Local Site Rebuilt | Start Data Repatriation. | Data syncs from Cloud back to Local. |
| System Restored | Cutover to Local Cluster. | SaaS returns to Local Body; Cloud returns to Shadow mode. |
4. Conclusion
By combining a 3-node Proxmox + Ceph HCI with cloud shadowing, this architecture achieves a “self-healing” 2+1 redundancy where 66% of the hardware sustains full service operation. It eliminates single points of failure by treating hardware as disposable commodity parts, utilizing an EC-based Hot Pool for live business data and a capacity-focused Cold Pool for local archives, while ensuring total site survival through an asynchronous cloud failover and repatriation loop.