

The “Running is Enough” Fallacy
In early-stage startups, the mantra is often “speed over everything.” Infrastructure is typically a reflection of this lean structure: a single monolithic server, manual backups, and a prayer against hardware failure. Many enterprises fall into the trap of equating “running” with “reliable.”
However, transitioning from a “project” to a SaaS Provider fundamentally changes the stakes. You are no longer just running code; you are managing client data and business continuity. What was “lean” at five people becomes negligent at five hundred clients. In this stage, ignoring security, scalability, and Cloud-Native principles isn’t saving time—it’s incurring massive technical and legal debt.
The Hidden Fragility of Non-HA Architectures
Without a High-Availability (HA) framework, your service exists in “Binary Survival”: it is either 100% up or 0% down. There is no middle ground, no graceful degradation.
-
SPOF Chain: In a “simple” setup, every component—from the ISP line to a single SSD—is a potential kill-switch. A $10 cable failure can trigger $10,000 in SLA penalties.
-
The Human Dependency Trap: Non-HA systems require “Heroic Ops.” Survival depends on an engineer’s sleep cycle rather than automated logic.
-
Configuration Drift: Hand-crafted servers become “Snowflakes.” If they die, they cannot be replicated, turning simple hardware failure into a catastrophic reconstruction project.
Surviving the Distributed World
To mitigate these risks, a Modern SaaS must shift from “Preventing Failure” to “Architecting for Failure.”
- Redundancy as Security: High Availability is a security feature. By ensuring that no single node holds the “keys to the kingdom,” you protect the service from both physical hardware failure and localized software exploits.
- Scalability as a Buffer: A Cloud-Native HA architecture allows you to scale horizontally. When a traffic spike hits, an HA system absorbs the load across multiple nodes; a “simple” system simply crashes, leading to database corruption and truncated logs.
- The Professional Standard: Customers today demand SLA (Service Level Agreements). If your architecture cannot support automated failover, you cannot legally or professionally guarantee the uptime required to compete in the global SaaS market.
2. Resilient Architecture: The “Self-Healing” Stack
From Fragile to Anti-Fragile
A “Self-Healing” stack shifts the engineering paradigm from Fragile (requiring manual repair) to Anti-Fragile (automated redundancy). We eliminate Single Points of Failure (SPOFs) by designing a coordinated mesh where node failure is a non-event for the end user.
The Engineering Logic of Self-Healing
To transition from concept to a functional stack, we implement two concrete pillars: Multi-Layered High Availability and Automated Infrastructure Restoration.
Pillar I: Multi-Layered High Availability
High Availability is not a single tool (like Keepalived); it is a series of redundant layers that work in concert to eliminate service disruption. We divide this into three critical tiers:

- Traffic Entry (Failover): Using Keepalived and VRRP, we create a Virtual IP (VIP). If the primary load balancer fails, traffic reroutes at the network level in seconds.

- The Traffic Entry Tier (Failover): This layer manages the “Service Identity.” We use Keepalived and the VRRP protocol to create a Virtual IP (VIP). This ensures that even if a physical load balancer node fails, the network traffic is rerouted at the Layer 3/4 level in seconds. This provides the first level of “survival” against hardware or OS crashes.

- Data Persistence (Consistency): We implement Master-Slave Synchronization with Read-Write Splitting. Transactional writes hit the Master, while resource-heavy reporting is isolated to Slaves, preventing “heavy queries” from performing a de facto DoS attack on the core system.

Pillar II: Infrastructure Disposability via Terraform
HA handles traffic continuity, but Infrastructure as Code (IaC) with Terraform fixes the underlying decay.
-
Stateless Compute: By offloading state to databases or shared storage, VMs become disposable.
-
The “Taint and Replace” Workflow:

-
- Detection: Monitoring (Zabbix) detects a persistent failure or configuration drift.
- Trigger: A WebHook triggers a CI/CD pipeline.
- Execution: Terraform marks the specific VM as
taintedand runs anapply. - Rebirth: The old VM is destroyed, and a new instance is cloned from a Cloud-init template. It joins the cluster with a clean OS and the exact configuration defined in the code.
- Security through Rebirth: This ensures that manual, undocumented changes (the leading cause of “it works on my machine” bugs) cannot survive.
3. High-Availability Implementation in Practice
To build a truly resilient SaaS, we must implement a deterministic path for data. This section breaks down the “Traffic-to-Data” journey using a proven enterprise-grade stack.
The Entry Point: Firewall and Layer 3/4 Failover
The architecture begins at the network edge. We avoid a single hardware dependency by creating a Virtual Entrance.
- Firewall Mapping: The external firewall maps incoming traffic on Port 443 (HTTPS) directly to a Virtual IP (VIP) within the service network. It does not point to a specific server.
- The Nginx-Keepalived Cluster: We deploy two identical Nginx Virtual Machines. Both run the Keepalived daemon.
- VIP Management: Keepalived uses the VRRP protocol to negotiate which Nginx node is the “Master.” The Master node holds the VIP.
- Failover Logic: If the Master Nginx node experiences a kernel panic or power loss, the Backup node detects the lack of heartbeats and immediately claims the VIP. To the external firewall and the end-user, the IP remains the same; only the MAC address on the backend has changed.
The Application Layer: Intelligent Load Balancing
Once the traffic reaches the active Nginx node, it must be distributed to the application servers. This is where we transition from Availability to Scalability.
- Nginx Upstream Groups: Instead of a static proxy, we define a pool of application servers (the “Cluster”).
upstream saas_app_cluster { server 172.16.10.11:8080 max_fails=3 fail_timeout=30s; server 172.16.10.12:8080 max_fails=3 fail_timeout=30s; check interval=3000 rise=2 fall=5 timeout=1000 type=http; } - Dynamic Health Checks: Nginx continuously monitors the backend group. If one application node becomes unresponsive (due to a memory leak or a crashed service), Nginx automatically removes it from the upstream rotation. The traffic is redistributed among the remaining healthy nodes, ensuring zero-impact to the user.
The Persistence Layer: Database Synchronization & Splitting
The database is the “Source of Truth” and requires a more nuanced approach than simple load balancing, as data consistency is paramount.
Master-Slave Synchronization
We utilize a high-performance synchronization protocol (such as MySQL Group Replication or PostgreSQL streaming replication).
- Primary (Master): Handles all Write (INSERT/UPDATE/DELETE) operations.
- Secondary (Slave): Continuously pulls binary logs or WAL files from the Master to maintain a near-identical state.
Database High Availability (DB-VIP)
Similar to the Nginx layer, the database cluster also utilizes Keepalived. The application servers connect to a DB-VIP. This ensures that if the Master database fails, a Slave can be promoted to Master, and the VIP will shift to the new Primary node. The application configuration never needs to be manually changed.
Read-Write Splitting for Performance Isolation
A common “SaaS Killer” is the resource-intensive analytical query (e.g., generating a year-end financial report).
- Transactional Traffic: Standard user actions (login, saving data) are routed to the Master node via the VIP.
- High-Load Reporting: We configure the reporting engine to connect directly to the Slave nodes.
- Result: Even if a complex report consumes 100% of the Slave’s CPU and I/O, the Master node remains untouched, ensuring that core transactional services stay fast and responsive for all other users.
We are discussing the architectural shift from manual system administration to Declarative Infrastructure. Even for an SME, this is the difference between an afternoon of panicked troubleshooting and a 120-second automated recovery.
4. Infrastructure as Code (IaC): The Architectural Logic of Rapid Recovery
For many SMEs, the transition to High-Availability often stops at the network layer. However, a truly resilient SaaS requires a Deterministic Recovery Layer. By using a declarative framework—as demonstrated in the jsonRAG project—we move from “hope-based” maintenance to an engineered Immune System.
The Strategic Shift: Declarative vs. Imperative Recovery
The traditional On-Prem architecture is “Imperative”: if a server fails, an engineer must manually execute a sequence of commands to fix it. This is slow, error-prone, and relies on human memory.
In a resilient architecture, we adopt a Declarative approach. We do not define how to fix a server; we define what a healthy server must look like.
- Portability of Identity: By defining the VM, networking, and security layers in Terraform, the “identity” of your application is no longer trapped in a single piece of hardware. It is a portable blueprint.
- Rapid Reconstruction: For an SME, the greatest risk is the “Snowflake Server”—a system so manually tweaked over time that it becomes impossible to rebuild from scratch. IaC ensures that the environment can be manifested or re-manifested at any time, on any host, with 100% fidelity.
Architectural Logic: Provisioning as a “Clean Room”
The logic behind the jsonRAG implementation is to treat every deployment as a “Clean Room” operation. The architecture decouples the lifecycle of the hardware from the lifecycle of the application.
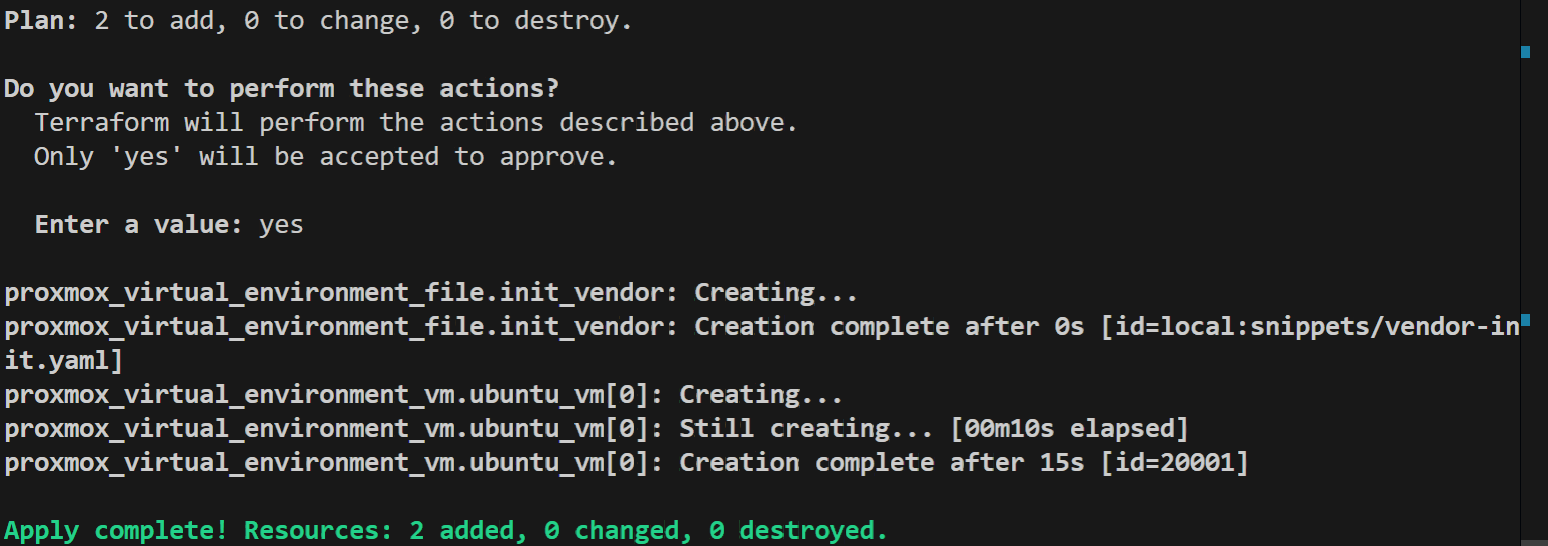
- Embedded Logic & Bootstrapping: In this architecture, all configuration settings, startup logic, and environment dependencies are baked into the code. The moment a node is initialized via Cloud-init, it autonomously executes the bootstrapping process—installing the runtime (Docker), pulling the service images, and applying environment-specific variables.
- Environment Injection: Rather than hard-coding secrets or local paths, the architecture utilizes external environment files. This allows the same architectural blueprint to be deployed across Development, Staging, and Production environments without changing a single line of infrastructure code.
Resilience in Practice: The “Taint-and-Rebuild” Cycle
This architecture turns the concept of “repair” on its head. When a node fails a health check—whether due to a silent file system corruption or a configuration error—the architectural response is Replacement.
By integrating the Observability discussed in Part 1 with this IaC logic, we close the resilience loop:
- Identification: The monitoring system identifies a node that has drifted from its “known good” state.
- Tainting: The architect (or an automated system) marks that specific instance as “invalid.”
- Execution: Terraform compares the current state to the code definition. Seeing a “tainted” resource, it destroys the old VM and triggers a fresh build.
The result is Infrastructure Immunity. The old, corrupted environment is wiped clean, and a fresh, pristine instance joins the cluster in minutes. For a small team, this provides a level of security and uptime that was previously only available to giant cloud providers.
5. Conclusion: The Resilience Loop
Resilience is not a single feature, but a continuous cycle of Observability, Availability, and Regeneration. Throughout this series, we have moved from simply “seeing” problems to building a system that can “survive” and “heal” from them.
- The Eyes (Observability): As discussed in Part 1, deep monitoring is the trigger. You cannot fix what you cannot see.
- The Body (High Availability): Through multi-layered redundancy—VIPs, Nginx clusters, and DB synchronization—we ensure the service remains standing even when individual components fail.
- The Immune System (IaC): By treating infrastructure as disposable code (as seen in jsonRAG), we ensure that recovery is deterministic and automated.
The professional standard for a modern SaaS is no longer to avoid failure, but to out-automate it. By embracing a declarative, self-healing stack, even a small team can provide a level of reliability that earns long-term customer trust. Architecture is our best defense; automation is our best recovery.